
深度学习的 GPU 环境的配置
本篇介绍如何在 Linux 服务器上安装 NVIDIA Driver(NVIDIA GPU 显卡驱动),CUDA Toolkit(GPU 通用并行计算架构),CUDA Deep Neural Network (cuDNN,CUDA 深度神经网络库),NVIDIA Collective Communications Library (NCCL,NVIDIA 集合通信库) 和 apex (NVIDIA/apex: A PyTorch Extension). 以 Ubuntu 18.04.6 LTS 为例进行介绍。
安装 NVIDIA Driver 和 CUDA Toolkit 需要考虑版本兼容问题,查看官方网站获取版本兼容对应关系。
NVIDIA Driver
该模块就是安装显卡驱动。
ubuntu18.04-nvidia drivers 10.2
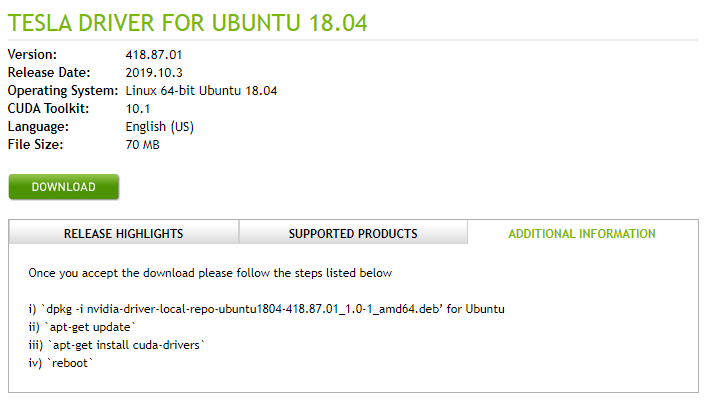
其实该步骤安装可以省略,在下一节安装 CUDA-TOOLKIT 时可同时选择安装驱动 NVIDIA-DRIVERS
1 | # 安装前需退出 X-SERVER,如 xorg 等,保证 `lsmod | grep nvidia` 返回为空 |
还有一种方法是直接使用系统命令检测合适的 GPU 显卡驱动版本,安装最适合的驱动版本
1 | # 更新系统 |
卸载驱动
1 | sudo apt-get remove --purge '^nvidia-.*' |
图形界面用户禁用 Nouvean
注意: 有些用户是 Ubuntu 图像界面使用者,默认集成了 Nouveau 驱动,在遇到 NVIDIA 显卡时默认安装。Nouveau 是由第三方为 NVIDIA 显卡开发的一个开源 3D 驱动,也没能得到 NVIDIA 的认可与支持。虽然 Nouveau Gallium3D 在游戏速度上还远远无法和 NVIDIA 官方私有驱动相提并论,不过却让 Linux 更容易的应对各种复杂的 NVIDIA 显卡环境,让用户安装完系统即可进入桌面并且有不错的显示效果。企业版的 Linux 更是如此,几乎所有支持图形界面的企业 Linux 发行版都将 Nouveau 收入其中。对于我们想要利用 GPU 在 Ubuntu 系统上训练深度学习模型的用户,Nouvean 对我们很不友好,安装 NVIDIA 驱动时总是会遇到 “ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver” 等错误。因此,我们需要先禁用 Nouveau 然后再安装 NVIDIA 显卡驱动。禁用 Nouveau 方法如下:
1 | # 查看是否使用 Nouvean 驱动 |
然后,重新生成 initramfs,更新系统内核
1 | sudo update-initramfs -u |
此时,重启系统 sudo shutdown -r now 后便可以安装 NVIDIA 驱动。这里有一个需要注意的点,因为禁用了 Nouvean 显卡驱动,且还未安装 NVIDIA 显卡驱动,此时,重启电脑后是进入不了图形界面的,需要进入终端界面,按下 ctrl + alt + f1 ~ ctrl + alt + f6 会进入终端命令行界面,在该界面按照上面的方法安装 NVIDIA 显卡驱动即可。安装完成后,就可以打开图形界面,快捷键是 ctrl + alt + f7,或者重启电脑。
CUDA Toolkit
cuda (Compute Unified Device Architecture) 模块为并行计算的加速包。CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU 能够解决复杂的计算问题。按照官方的说法是,CUDA是一个并行计算平台和编程模型,能够使得使用GPU进行通用计算变得简单和优雅。
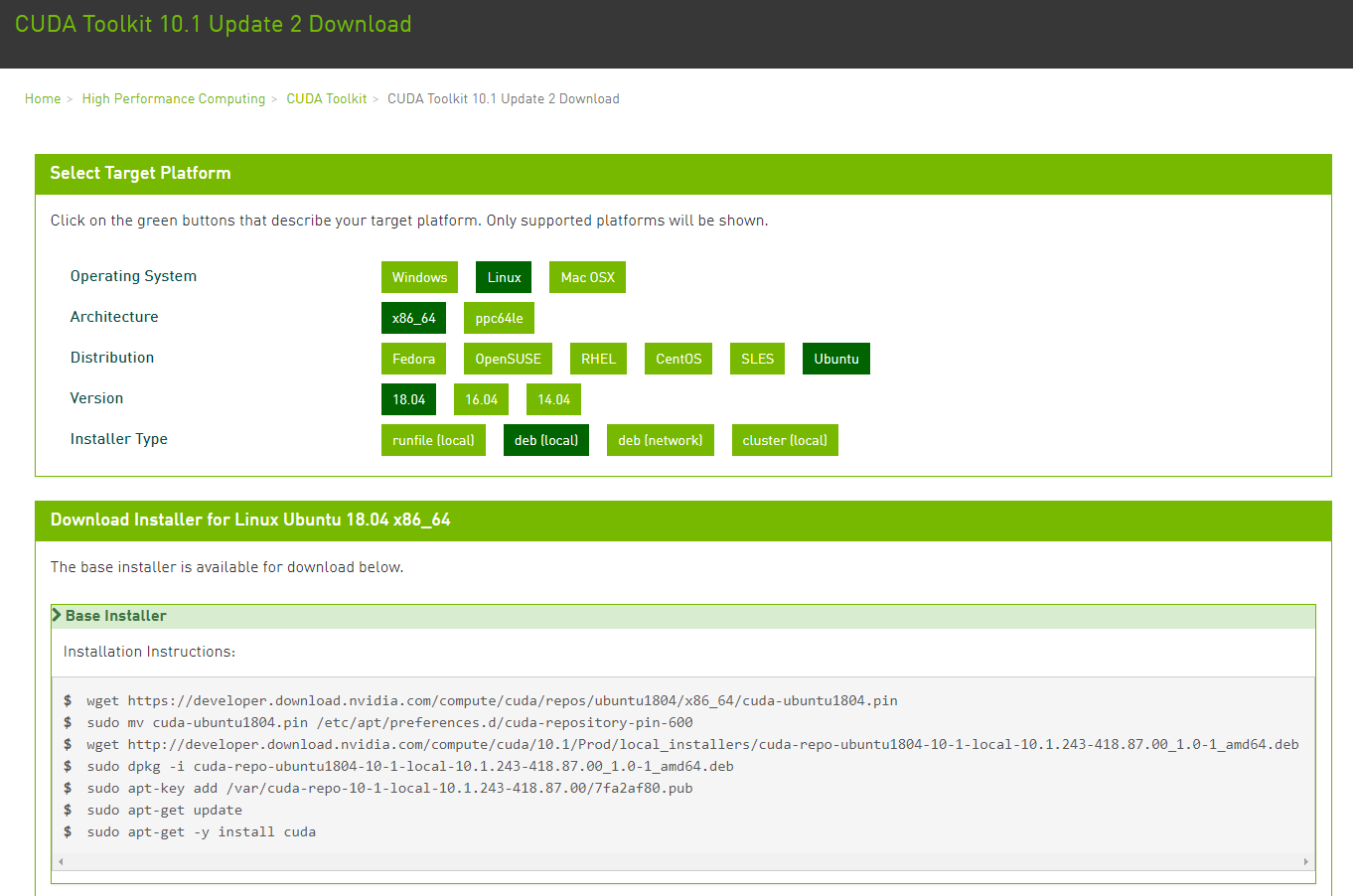
1 | wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run |
最新版的安装中只需要使用方向键和 Enter 键就可以在一个界面中选择安装内容。不过与下面的是一回事。
在安装过程中截取其中比较重要的几个选择:
1 | Do you accept the previously read EULA? |
安装完后,记得配置环境,在下一节注意中有详细的配置方法。
1 | # 查看安装是否成功 |
卸载
1 | # 最简单的方法,注意我这里按照的是 cuda10.2 |
cuDNN
cudnn 模块其实就是一个专门为深度学习计算设计的软件库,里面提供了很多专门的计算函数,如卷积等。
cudnn 下载时需要登录,下载对应的版本:cudnn
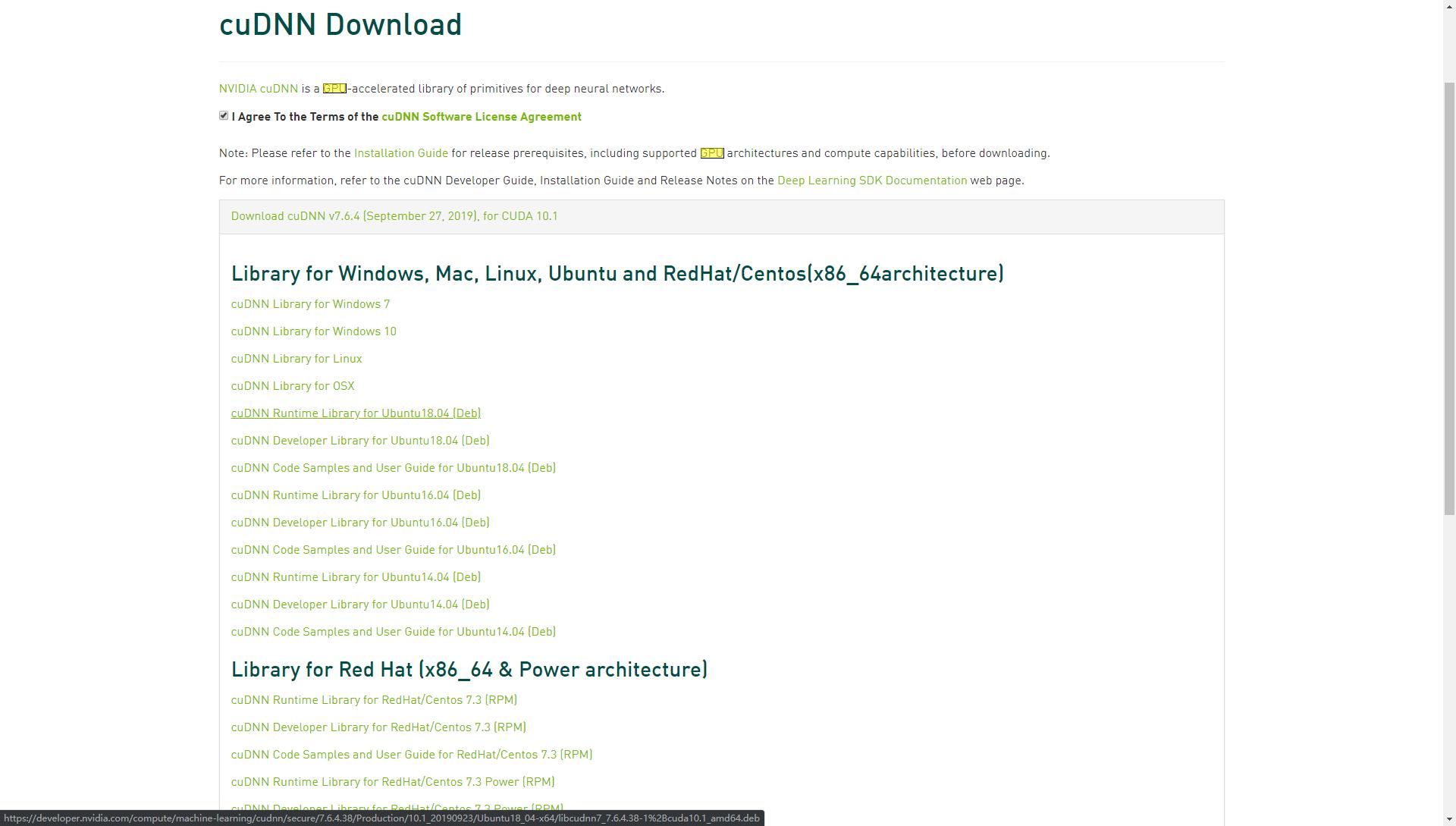
然后,【建议】参考官网 NVIDIA CUDNN DOCUMENTATION 【获取最新】安装
1 | # 旧版本 |
1 | # 新版本 |
判断是否(拷贝)安装 cudnn成功:
1 | # 注意新版本使用 cudnn_version.h;旧版本使用 cudnn.h |
如果输出有类似下面的结果,说明安装成功:
1 | #define CUDNN_MAJOR 8 |
配置环境变量
注意: 安装完 cuda drivers, cudatoolkit, cudnn 后需要把 cuda 添加到环境变量,方法如下
需要把 CUDA_HOME 添加到环境变量,一般 CUDA_HOME=/usr/locdal/cuda-*/bin,我的配置如下
1
2
3export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=$CUDA_HOME/bin:$PATH一种简单的方法是在命令行输入以下命令:
1
2
3
4
5cat >> ~/.bashrc <<-"EOF"
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=$CUDA_HOME/bin:$PATH
EOF然后使环境变量生效:
1
source ~/.bashrc
环境变量配置后,可以运行
nvidia-smi和nvcc --version来检验是否安装和配置成功。
注解:
- ${variable:-word} 代表,如果variable有给值,则以variable设定的文字为主,如未给值,则以word字串为主
- ${variable:+word} 代表,如果variable有给值,则值为word;如果variable未给值,则最后结果为空字串(empty)。
NCCL
当使用多 GPU 进行训练模型时,还需要安装 NCCL(The NVIDIA® Collective Communications Library ™, pronounced “Nickel”, is a library of multi-GPU collective communication primitives that are topology-aware and can be easily integrated into applications. NCCL provides fast collectives over multiple GPUs both within and across nodes. It supports a variety of interconnect technologies including PCIe, NVLink™ , InfiniBand Verbs, and IP sockets. NCCL also automatically patterns its communication strategy to match the system’s underlying GPU interconnect topology.)。安装 NCCL 还需要如下两个条件,一个是软件条件,一个是硬件条件。
软件条件
软件条件是主机上必须安装有:
- glibc 2.17 或更高版本;
- CUDA 10.0 或更高版本;
glibc(The GUN C Library),是 C 标准库的开源实现,检查主机上该库的版本:
1 | # ldd 命令可用于检查 glibc 的版本。在大多数情况下,以下命令打印与 glibc 相同的版本 |
CUDA 版本根据上面的安装可以知道。当按照上面的安装成功后,并正确配置了环境变量,使用命令查看 CUDA 版本:
1 | nvcc -V |
硬件条件
NCCL 支持计算能力为 3.5 及更高版本的所有 CUDA 设备。有关所有 NVIDIA GPU 的计算能力,请检查:CUDA GPU。
安装 NCCL
这里给出 Ubuntu 安装的方法,其他 Linux 发行版请参考 NVIDIA 官网
- 访问 NVIDIA NCCL 主页,下载对应 CUDA 版本的 NCCL

上面显示的是最新版本的,如果想要下载历史版本的,可以点击 NCCL legacy Downloads 获取历史版本,大概如下图

- 安装NCCL,这里又分3类安装方式:
- 本地简洁安装
下载 O/S agnostic local installer 里面的 nccl-.txz ,然后解压编译应用程序时,指定安装 NCCL 的目录路径,例如:1
2
3
4sudo cp nccl_2.18.3-1+cuda11.0_x86_64.txz /usr/local
cd /usr/local
sudo tar xvf nccl_2.18.3-1+cuda11.0_x86_64.txz
sudo rm nccl_2.18.3-1+cuda11.0_x86_64.txz/usr/local/nccl-<version>/ - 本地存储库安装
下载 Local installer for Ubuntu 18.04 (我这里是18.04,请个人根据自己的系统版本下载) 里面的 nccl-local-repo-ubuntu1804-2.15.5-cuda11.8_1.0-1_amd64.deb,然后进行安装:1
2
3
4
5
6
7
8
9# 先安装本地 NCCL 存储库
# 地存储库安装将提示您安装它嵌入的本地密钥以及用于签名包的本地密钥。请务必按照说明安装本地密钥,否则安装阶段稍后将会失败。
sudo dpkg -i nccl-local-repo-ubuntu1804-2.15.5-cuda11.8_1.0-1_amd64.deb
# 更新 APT 数据库
sudo apt update
# 使用 APT 安装 libnccl2 软件包。此外,如果您需要使用 NCCL 编译应用程序,也可以安装 libnccl-dev 软件包
sudo apt install libnccl2 libnccl-dev - 联网存储库安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 下载 证书链
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-keyring_1.0-1_all.deb
# 安装证书链
sudo dpkg -i cuda-keyring_1.0-1_all.deb
# 更新 APT 数据库
sudo apt-get update
# 安装最新版
sudo apt install libnccl2 libnccl-dev
# 安装指定版
sudo apt install libnccl2=2.15.5-1+cuda11.8 libnccl-dev=2.15.5-1+cuda11.8
- 本地简洁安装
如果安装有 CUDA 版 PyTorch,那么会默认安装有 nccl,路径在:lib/python3.x/site-packages/torch/cuda/nccl.py,因此,当使用 GPU 把 PyTorch 时可以不用在 Ubuntu 系统上安装 NCCL.
验证 NCCL
1 | # 安装 locate |
APEX
APEX(Automatic Mixed Precision) 包用于简化 Pytorch 中的混合精度和分布式训练,加速模型训练。APEX 是来自英伟达 (NVIDIA) 的一个很好用的深度学习加速库。由英伟达开源,完美支持PyTorch框架,用于改变数据格式来减小模型显存占用的工具。其中最有价值的是 amp (Automatic Mixed Precision) ,将模型的大部分操作都用 Float16 数据类型测试,一些特别操作仍然使用 Float32。并且用户仅仅通过三行代码即可完美将自己的训练代码迁移到该模型。实验证明,使用 Float16 作为大部分操作的数据类型,并没有降低参数,在一些实验中,反而由于可以增大 Batch size,带来精度上的提升,以及训练速度上的提升。
APEX 作为 Python 的一个库进行使用,安装使用 pip 进行,参考官网GITHUB:
1 | git clone https://github.com/NVIDIA/apex |
安装需要编译一段时间,请耐心等待直到安装成功。
莫名 nvidia-smi 无法使用的解决方法
在平常使用时,偶尔会出现命令 nvidia-smi 无法使用的情况,这种一般是 Linux 内核更新导致的,一种解决方法如下:
1 | # 安装头文件 |
问题分析:这是由于 Ubuntu 自动更新内核版本导致的,可以使用如下命令关闭自动更新
1 | $ sudo apt-mark hold linux-image-generic linux-headers-generic |
如果要重新启用内核更新,可以用如下命令
1 | $ sudo apt-mark unhold linux-image-generic linux-headers-generic |
运行深度学习模型时可能遇到的问题
- 运行大模型时出现:CUDA error: uncorrectable ECC error encountered?
ECC is Error Correcting Code. It is not unique to GPUs. On GPUs, it is a feature that uses extra memory bits to store error information, so that if an error (of particular severity) occurs in the memory subsystem it can either be detected and reported, or detected and corrected. 当出现 ECC 错误很有可能表示当前使用的 GPU 硬件出问题。可以更换其他 GPU 尝试是否能够正确运行程序。
参考链接
- NVIDIA CUDA Installation Guide for Linux
- gpu 的驱动,cuda,cudnn的关系
- Ubuntu下安装CUDA
- 显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?
- Ubuntu – Removing Nvidia CUDA Toolkit and installing new one
- Ubuntu系统—系统驱动丢失、Kernel内核卸载、禁止更新
- Ubuntu内核(更新和卸载内核、取消自动更新)
- Check glibc Version in Linux
- NVIDIA Deep Learning NCCL Documentation
- How to Disable the Nouveau Driver for Different Linux Systems
- Ubuntu 安装 NVIDIA 显卡驱动详细步骤(ERROR: The Nouveau kernel driver is currently in use by your system)
- cuda安装失败问题2:install of driver component failed







