本笔记是依据 Apache Flink 官网关于独立集群部署的步骤,进行 Flink 分布式集群部署的具体过程。虽然按照官网步骤能够完成,但是实际部署中还是会遇到一些坑,这里根据个人真实的部署过程做一个详细的记录,以备后续查阅和帮助有需要的人参考。除此之外,Flink 还可以部署在 Yarn, K8s等。
部署环境是Ubuntu 18.04.3 LTS,Java 1.8.0_231,Flink 1.9.0;三台机器,分别是master: 1.1.1.0, worker1: 1.1.1.1, worker2: 1.1.1.2,其中节点机器master作为 Jobmanager, 其他两个节点机器worker1, worker2作为TaskManager. 下面一步一步从零开始 Flink 分布式集群部署(不包括 Ubuntu 18.04.03 LTS 的安装),其中 Java 在 master, worker1, worker2 中的安装是一样,这里以master为例。Flink 部署首先在 master 配置,然后拷贝到worker1, worker2. 注意,Flink集群的运行不需要 Zookeeper 的支持。
Java 1.8.0_231 和 Flink 1.9.0 下载
Java 1.8.0_231 下载
打开浏览器,输入网址:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html,选择相应的版本下载即可。
Flink 1.9.0 下载
把网址https://flink.apache.org/downloads.html 输入浏览器地址栏,进入Flink下载界面,找到Apache Flink 1.9.1下面的Apache Flink 1.9.1 for Scala 2.11 (asc, sha512) ,点击下载即可。这里不选择Apache Flink 1.9.1 for Scala 2.12 (asc, sha512)是因为该版本不能够运行scala local shell,对此没有要求的也可以选择使用此版本。
两者都下载后,在终端查看如下:
1
2
3
| jinzhongxu@master:~$ ls -lh *gz
-rwxrwxr-x 1 jinzhongxu jinzhongxu 244M 12月 24 21:50 flink-1.9.1-bin-scala_2.11.tgz
-rwxrwxr-x 1 jinzhongxu jinzhongxu 186M 12月 17 18:08 jdk-8u231-linux-x64.tar.gz
|
安装 Java 和 Flink 以及配置环境
安装 Java
在终端输入以下命令,解压 jdk-8u231-linux-x64.tar.gz,如下
1
| jinzhongxu@master:~$ tar -xzf jdk-8u231-linux-x64.tar.gz
|
查看解压结果
1
2
| jinzhongxu@master:~$ ls -lhd jdk1.8.0*
drwxr-xr-x 7 jinzhongxu jinzhongxu 4.0K 10月 5 18:13 jdk1.8.0_231
|
一般为了简洁,我会重新命名该文件夹,当然这步不是必须的,以个人喜好
1
| jinzhongxu@master:~$ mv jdk1.8.0_231/ jdk8
|
配置Java 环境
将 Java 路径写入 .bashrc 文件中
1
| jinzhongxu@master:~$ vim .bashrc
|
添加如下代码
1
2
| JAVA_HOME=/home/jinzhongxu/jdk8
export PATH=$PATH:$JAVA_HOME/bin
|
此时,在终端中输入以下命令,看到如下返回结果,说明已经安装好 Java
1
2
3
4
5
6
| jinzhongxu@master:~$ java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
jinzhongxu@master:~$ javac -version
javac 1.8.0_231
|
注意 :把 JAVA_HOME 写入 /etc/profile 文件中,如果不这样做,实际经验告诉我,Flink 单机启动时会报 JAVA_HOME 问题;Flink 集群启动时,不能启动没有配置该项的 worker 的 Taskmanger
命令如下:
1
| jinzhongxu@master:~$ vim /etc/profile
|
添加如下代码
1
| export JAVA_HOME=/home/jinzhongxu/jdk8
|
按照这个步骤,分别在master, worker1, worker2上部署 Java.
安装 Flink
在终端中运行如下命令
1
2
3
4
| jinzhongxu@master:~$ tar -xzf flink-1.9.1-bin-scala_2.11.tgz
jinzhongxu@master:~$ ls -lhd flink-1.9.1*
drwxr-xr-x 10 jinzhongxu jinzhongxu 4.0K 9月 30 15:10 flink-1.9.1
-rwxrwxr-x 1 jinzhongxu jinzhongxu 244M 12月 24 21:50 flink-1.9.1-bin-scala_2.11.tgz
|
一般为了简洁,我会重新命名该文件夹,当然这步不是必须的,同样也是以个人喜好
1
| jinzhongxu@master:~$ mv flink-1.9.1 flink
|
配置 Flink 环境
配置 flink, 在命令行中输入如下命令
1
| jinzhongxu@master:~$ vim flink/conf/flink-conf.yaml
|
修改如下代码
注意这里假设在 /etc/hosts 中配置了IP地址解析
1
| jobmanager.rpc.address: master
|
配置 slaves, 在命令行中输入如下命令
注意在flink1.11.0版本中已经将salves替换为worker,这很可能是最近计算机界对反对种族歧视的调整
1
| jinzhongxu@master:~$ vim flink/conf/slaves
|
修改代码:删除 localhost,增加如下两个机器节点,也可以输入ip 地址,这里输入的是 hostname
如果想让master主机同时也作为一个taskmanger,可以增加master
根据需要,一般需要调整每个taskmanager上的插槽slots的数量和默认并行运行代码的能力,配置方法如下,注意,slots的会平分内存,但设定slots个数时一般是安装cpu核心数
1
2
3
4
5
| # 每个taskmanger的能力,我这里CPU是5核心的
taskmanager.numberOfTaskSlots: 5
# 默认代码运行的并行数
parallelism.default: 3
|
并行数设定的优先级是:代码中设置最高、提交代码时指定的次之、配置文件中默认的最低
至此,master 节点已经配置完成
安装 worker1 和 worker2 的 Flink
通过 scp 来拷贝 master 的 flink 到 worker1 和 worker2 节点上,命令如下:
1
2
| jinzhongxu@master:~$ scp -r flink worker1:/home/jinzhongxu/.
jinzhongxu@master:~$ scp -r flink worker2:/home/jinzhongxu/.
|
**注意:master 和 worker1, worker2 不仅具有相同的 Java 环境,Flink 环境,还具有相同的用户名,三者之间通过ssh 连接和传送信息。如何配置 ssh 下面将会补充该部分。如何修改机器的hostname 请参考下面部分 **
此时,就可以运行 Flink 集群了。在 master 命令行中输入如下命令
1
2
3
4
5
| jinzhongxu@master:~$ ./flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host worker1.
Starting taskexecutor daemon on host worker2.
|
可以看到已经启动了 Flink Cluster,其中 standalonesession daemon 在 master 节点上,taskexecutor 分别在 worker1 和 worker2 上启动。
启动过程如下:在master节点先启动本机的jobmanager,然后SSH连接到worker1, worker2,启动taskmanager.
关闭命令如下:
在master节点上
1
| ./flink/bin/stop-cluster.sh
|
关闭过程如下:在master运行关闭脚本,首先通过SSH连接到worker1, worker2,关闭taskmanager,然后再关闭master本机的jobmanager。
如果想关闭某个节点,可以直接在该节点机器上运行如下命令
1
2
3
4
5
6
7
| ./flink/bin/jobmanager.sh start
./flink/bin/jobmanager.sh stop
./flink/bin/taskmanager.sh start
./flink/bin/taskmanager.sh stop
|
在 master 节点运行 jps 命令,可以发现
1
2
3
| jinzhongxu@master:~$ jps
10260 StandaloneSessionClusterEntrypoint
10319 Jps
|
在 worker1 节点运行 jps 命令,可以发现
1
2
3
| jinzhongxu@worker1:~$ jps
7324 TaskManagerRunner
7375 Jps
|
在 worker2 节点运行 jps 命令,可以发现
1
2
3
| jinzhongxu@worker2:~$ jps
5562 TaskManagerRunner
5612 Jps
|
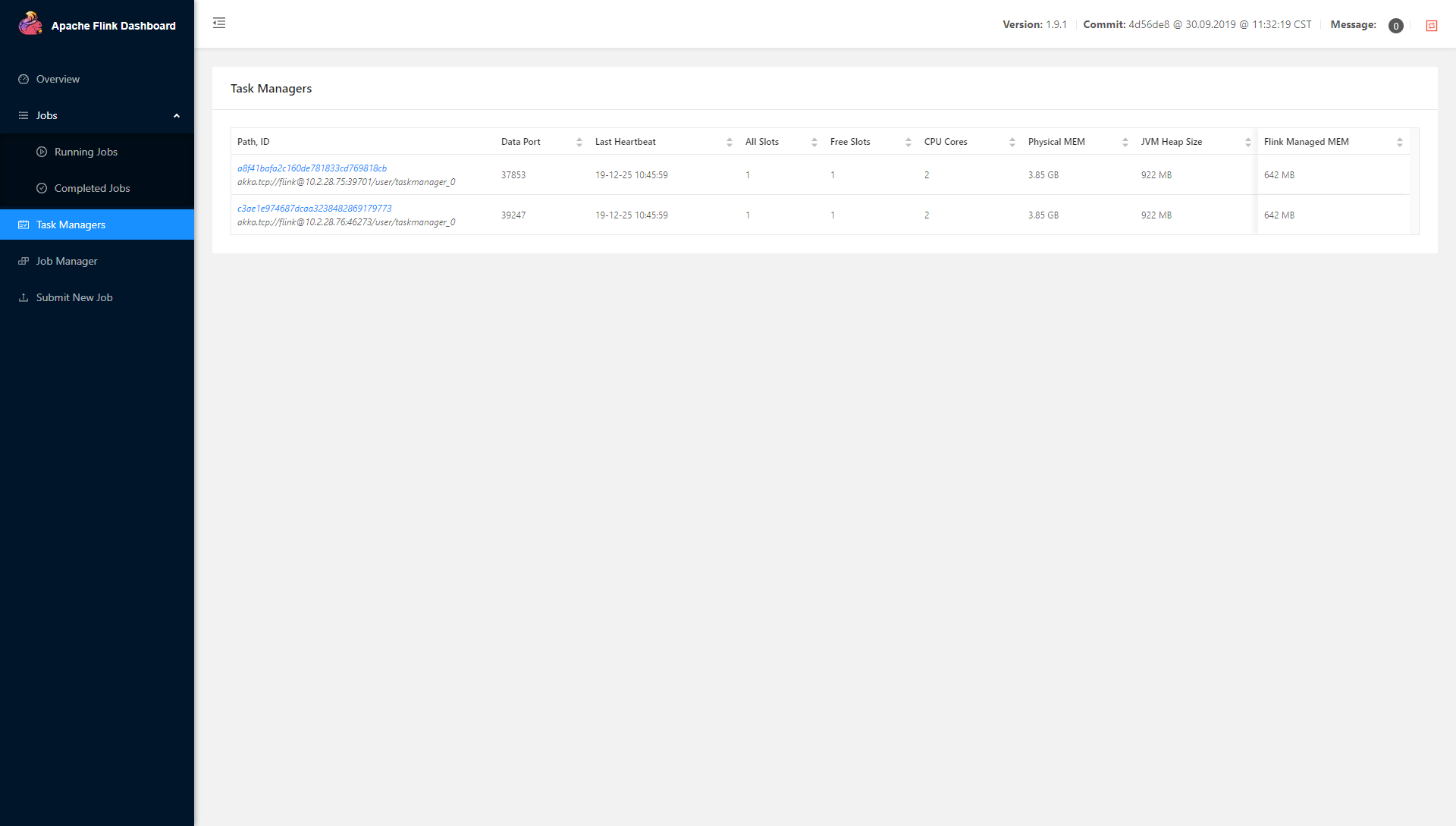
同时,在浏览器上输入 http://1.1.1.0:8081/ 或 http://master:8081/ 可以发现 Apache Flink Dashboard 已经正常启动,在 Task Managers 中可以看到如下页面
在 master 终端中输入 ,运行批处理模板里的wordcount程序,指定并行数2
1
| jinzhongxu@master:~$ ./flink/bin/flink run -p 2 ./flink/examples/batch/WordCount.jar
|
可以看到
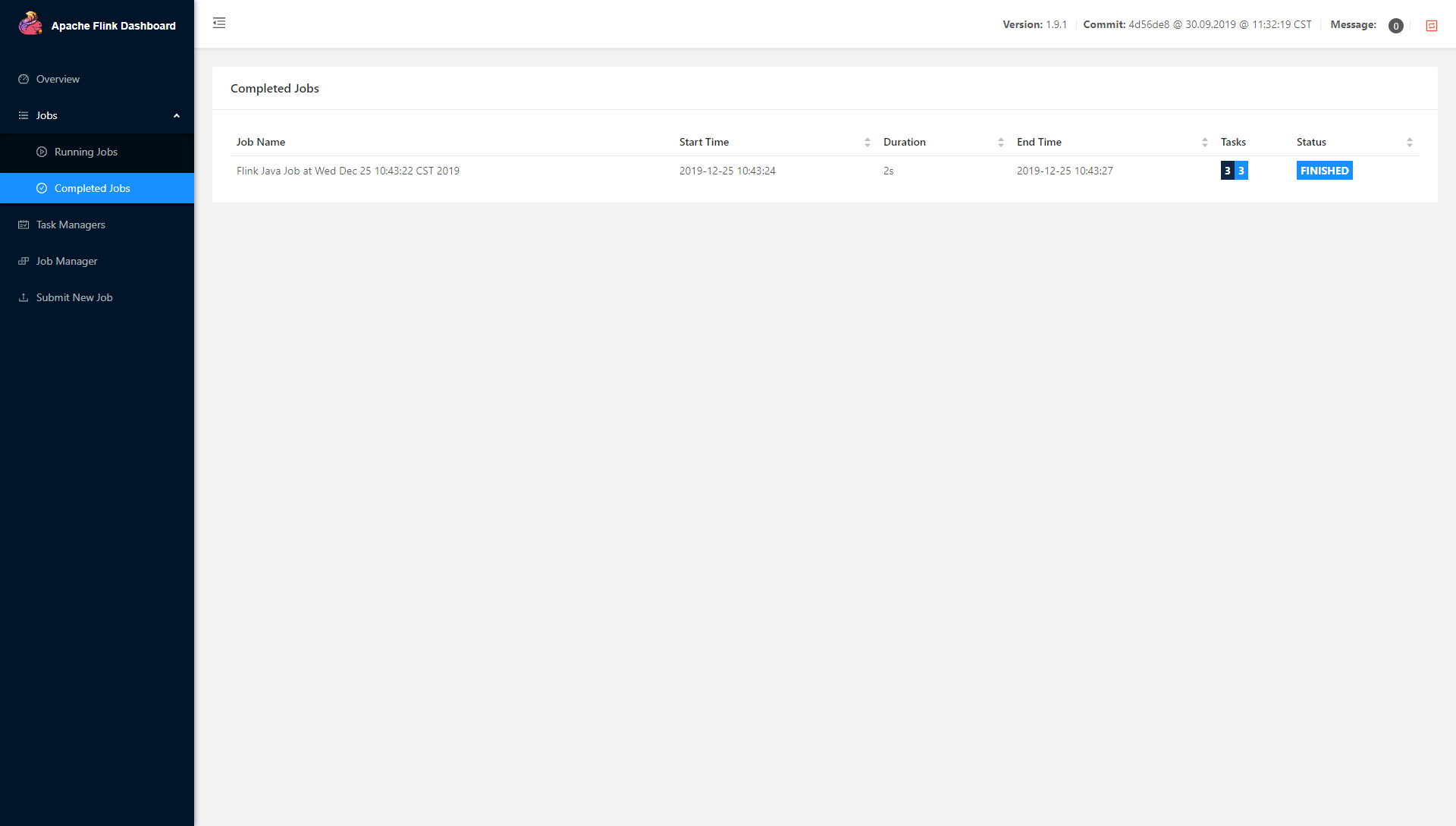
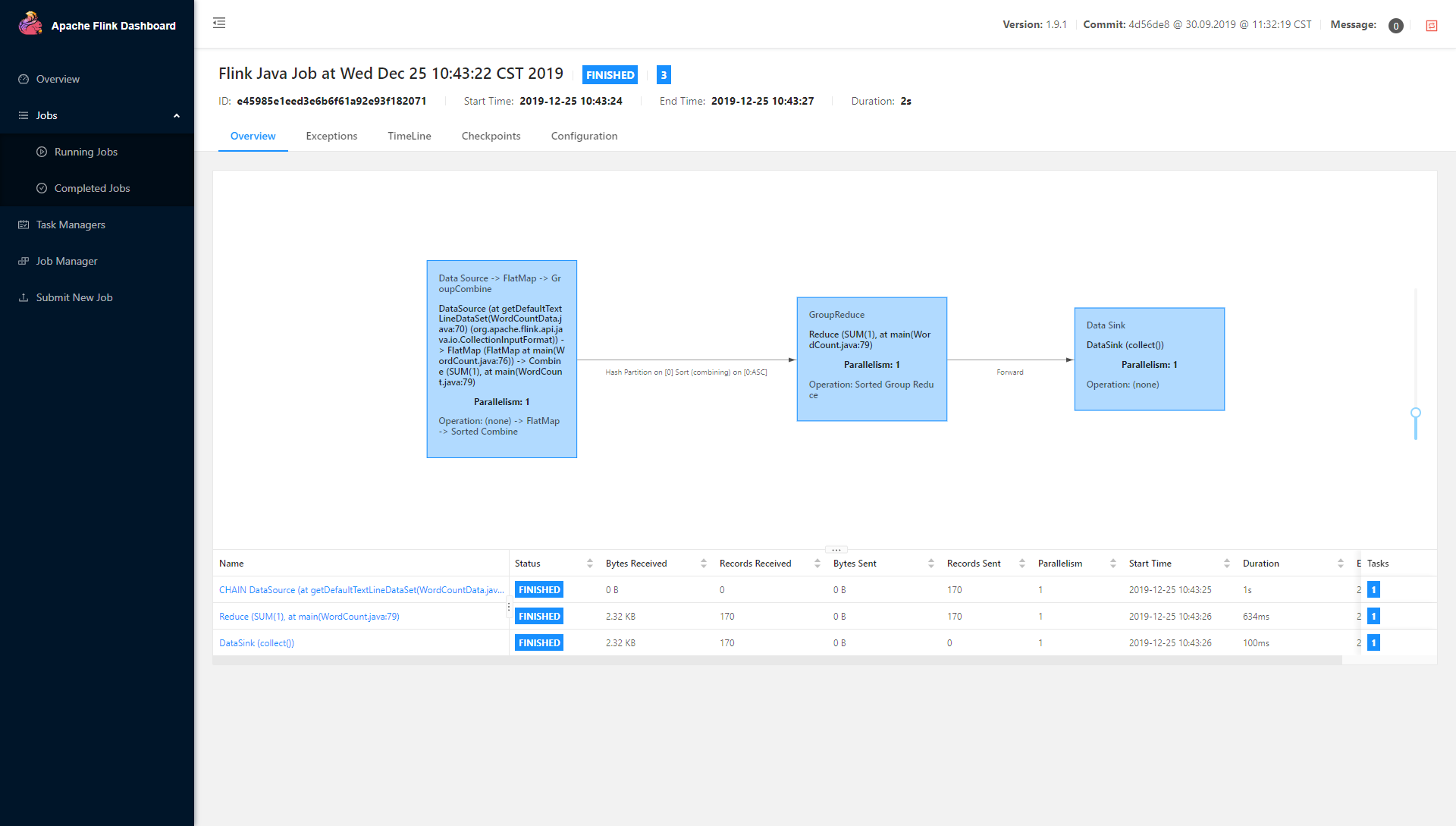
看到这些说明,分布式部署的 Flink 已经成功。也可以在web页面通过最下面选项的 submit new job来提交,里面同样可以设置并行数和其他参数等。
Flink 结构及开发
Flink 代码编程时,一般分为 创建环境 -> 定义source -> 定义transformation -> 定义sink. Flink 中把所有的数据都作为流进行处理,其中批数据就是有界流,其他是无界流。
Flink 的其他特点如下:
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统可以连接
- 高可用,可动态扩展,7*24小时全天候运行
与spark streaming的区别,spark 是天生批处理,使用微小的分块实现类似功能的流处理,但内部还是使用批处理引擎。
Flink 提交jar后,在client上会进行优化,生成 StreamGraph -> JobGraph,之后在Jobmanger上生成 ExecutionGraph,真正执行时又会生成物理图。
在写代码之前,一般需要配置pom
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>FlinkKafka</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
|
配置完后,就可以写代码了,根据 Flink 的结构,首先,创建环境,这里以scala代码为例,一般使用
1
| val env = StreamExecutionEnvironment.getExecutionEnvironment
|
而不是使用
1
2
| # 创建本地运行环境
val env = StreamExecutionEnvironment.createLocalEnvironment
|
1
2
| # 创建集群执行运行环境
val env = ExecutionEnvironment.createRemoteEnvironment("jobmanage-hostnamne", 6123, "YOURPATH//wordcout.jar")
|
这里给出一个简单的 wordcount 程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| package org.example.wc
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val inputPath = "src\\main\\resources\\hello.txt"
val inputDataSet = env.readTextFile(inputPath)
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map((_, 1)).setParallelism(3)
.groupBy(0)
.sum(1).setParallelism(1)
wordCountDataSet.print()
}
}
|
因为 Flink 天生是处理流数据的,那么流数据的wordcount代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| package org.example.wc
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = env.socketTextStream("8.6.8.6", 7777)
val wordCountDataStream = dataStream.flatMap(_.split(" "))
.filter(_.nonEmpty).setParallelism(4)
.map((_, 1)).setParallelism(4)
.keyBy(0)
.sum(1).setParallelism(1)
wordCountDataStream.print().setParallelism(3)
env.execute("stream word count job")
}
}
|
运行代码后,在主机 8.6.8.6 终端运行
1
2
3
| # -l 表示打开一个listen,-k 表示keeplive,7777 表示端口
nc -lk 7777
> hello world
|
其次,对于source
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
| package org.example.apitest
import java.util.{Properties, Random}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1 = env.fromCollection(List(
SensorReading("sensor_1", 1548822923, 35.283928372938),
SensorReading("sensor_2", 1782939192, 35.828372928373),
SensorReading("sensor_3", 1759283827, 36.928381738283),
SensorReading("sensor_4", 1872928372, 26.293828372839)
))
val stream2 = env.readTextFile("src\\main\\resources\\sensor.txt")
val stream3 = env.fromElements(1, 2.0, "string")
val properties = new Properties()
properties.setProperty("bootstrap.servers", "1.1.1.255:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val stream4 = env.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), properties))
val stream5 = env.addSource(new SensorSource())
stream5.print("stream").setParallelism(3)
env.execute("source test")
}
}
class SensorSource() extends SourceFunction[SensorReading] {
var running: Boolean = true
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
val rand = new Random()
var curTemp = 1.to(10).map(
i => ("sensor_" + i, 60 + rand.nextGaussian() * 20)
)
while (running) {
curTemp = curTemp.map(
t => (t._1, t._2 + rand.nextGaussian())
)
val curTime = System.currentTimeMillis()
curTemp.foreach(
t => sourceContext.collect(SensorReading(t._1, curTime, t._2))
)
Thread.sleep(500)
}
}
override def cancel(): Unit = {
running = false
}
}
|
补充1:配置 SSH
首先,分别在各集群机器(这里是 Ubuntu 系统)上运行如下命令,安装 SSHD 服务
1
| jinzhongxu@master:~$ sudo apt update && sudo apt install openssh-server
|
其次,创建 SSH 公钥和私钥
1
| jinzhongxu@master:~$ ssh-keygen -t rsa
|
然后,在 master 节点创建 authorized_keys 文件,用于认证 SSH 连接
1
2
| jinzhongxu@master:~$ touch ./.ssh/authorized_keys
jinzhongxu@master:~$ chmod 600 ./.ssh/authorized_keys
|
再然后,将所有机器的公钥写入 master 节点上的 authorized_keys 文件
1
| jinzhongxu@master:~$ cat ./.ssh/id_rsa.pub >> ./.ssh/authorized_keys
|
1
2
3
4
5
| jinzhongxu@master:~$ scp worker1:/home/jinzhongxu/.ssh/id_rsa.pub worker1.pub
jinzhongxu@master:~$ cat worker1.pub >> ./.ssh/authorized_keys
jinzhongxu@worker1:~$ ssh-copy-id .ssh/id_rsa.pub master
|
1
2
3
4
5
| jinzhongxu@master:~$ scp worker2:/home/jinzhongxu/.ssh/id_rsa.pub worker2.pub
jinzhongxu@master:~$ cat worker2.pub >> ./.ssh/authorized_keys
jinzhongxu@worker2:~$ ssh-copy-id .ssh/id_rsa.pub master
|
最后,将 master 中的 authorized_keys 传给 worker1, worker2
1
2
| jinzhongxu@master:~$ scp ./.ssh/authorized_keys worker1:/home/jinzhongxu/.ssh/.
jinzhongxu@master:~$ scp ./.ssh/authorized_keys worker1:/home/jinzhongxu/.ssh/.
|
补充2:修改主机名
下面以 master 为例,修改服务器主机名
首先,查看目前主机名
1
2
| jinzhongxu@DESKTOP-5397GNE:~$ hostname
DESKTOP-5397GNE
|
其次,修改主机名
1
| jinzhongxu@DESKTOP-5397GNE:~$ sudo vim /etc/hostname
|
删除 DESKTOP-5397GNE 修改为 master
然后,修改 hosts
1
| jinzhongxu@DESKTOP-5397GNE:~$ sudo vim /etc/hosts
|
修改内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 127.0.0.1 localhost
127.0.1.1 master
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
10.2.28.74 master
10.2.28.75 worker1
10.2.28.76 worker2
|
需要重启电脑,才能在命令行正确显示主机名,查看主机名
1
2
| jinzhongxu@master:~$ hostname
master
|
类似于 master,对于其他 worker1 和 worker2 同样方法进行修改。











